
OpenAI has announced GPT-4 — their highly anticipated next-generation AI model — and released early previews to API customers and ChatGPT Plus subscribers. From The Verge:
The company claims the model is “more creative and collaborative than ever before” and “can solve difficult problems with greater accuracy.” It can parse both text and image input, though it can only respond via text. OpenAI also cautions that the systems retain many of the same problems as earlier language models, including a tendency to make up information (or “hallucinate”) and the capacity to generate violent and harmful text.
OpenAI says it’s already partnered with a number of companies to integrate GPT-4 into their products, including Duolingo, Stripe, and Khan Academy. The new model is available to the general public via ChatGPT Plus, OpenAI’s $20 monthly ChatGPT subscription, and is powering Microsoft’s Bing chatbot. It will also be accessible as an API for developers to build on.
By now, everyone has seen the image that set the internet on fire back in January.
This image went viral months before GPT-4 launched, inspiring excitement and fear about the potential of AI. It makes GPT-4 seem incredibly more capable than the previous models... yet, in practice, the improvement isn’t nearly as drastic as the image makes it seem.
Using GPT-4
ChatGPT Plus has had access to GPT-4 since the day it was released, and I’ve been playing around with the new model.
The new version of GPT feels smarter than the previous model, but if I’m being honest, it’s definitely not the “huge-leap forward” that ChatGPT was compared the previous GPT-3 playground. That said, some quick tests help prove that this new version is definitely more capable than its predecessor.
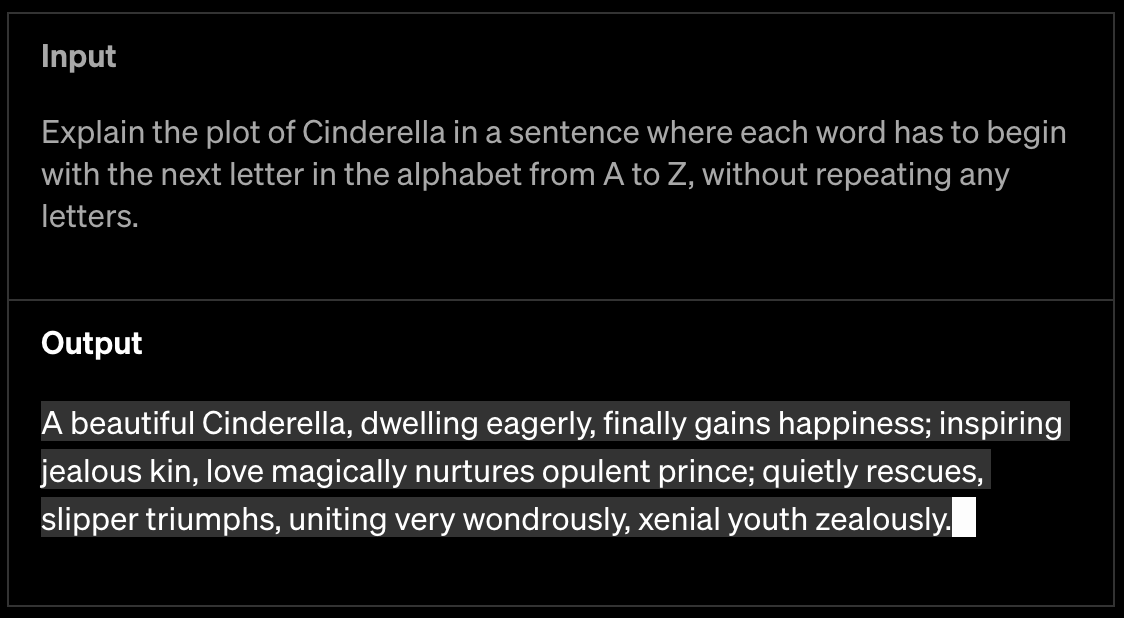
I fed GPT-3.5 the same “describe the plot of Cinderella using every letter in the alphabet A-Z” prompt used above... and got an answer that was missing half the alphabet.
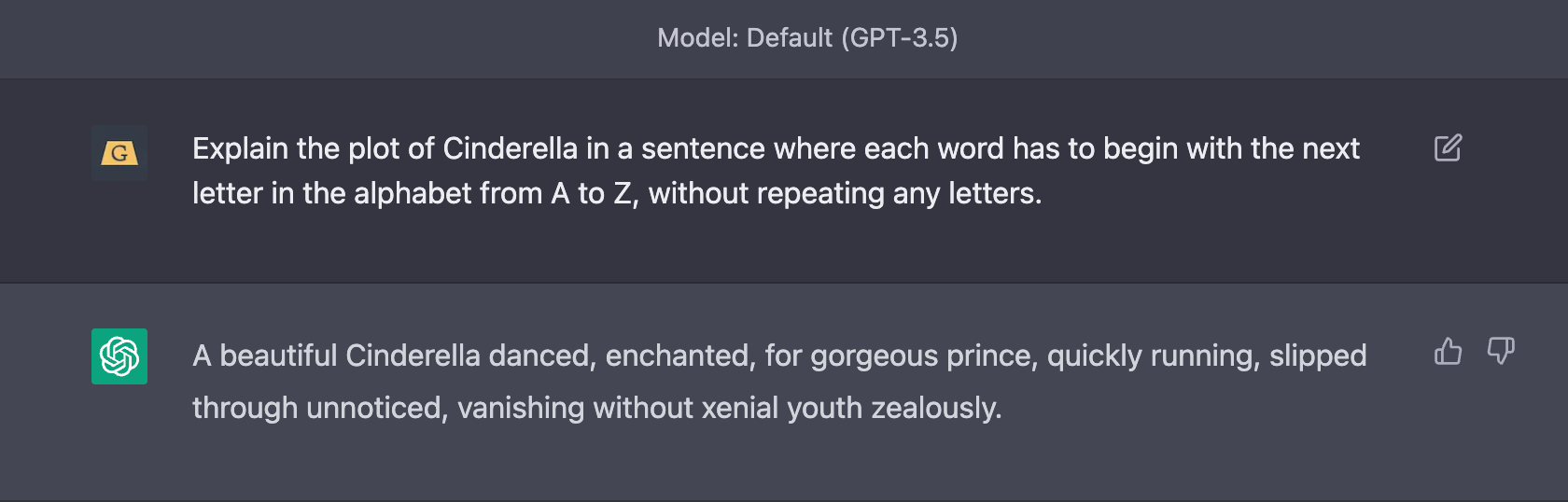
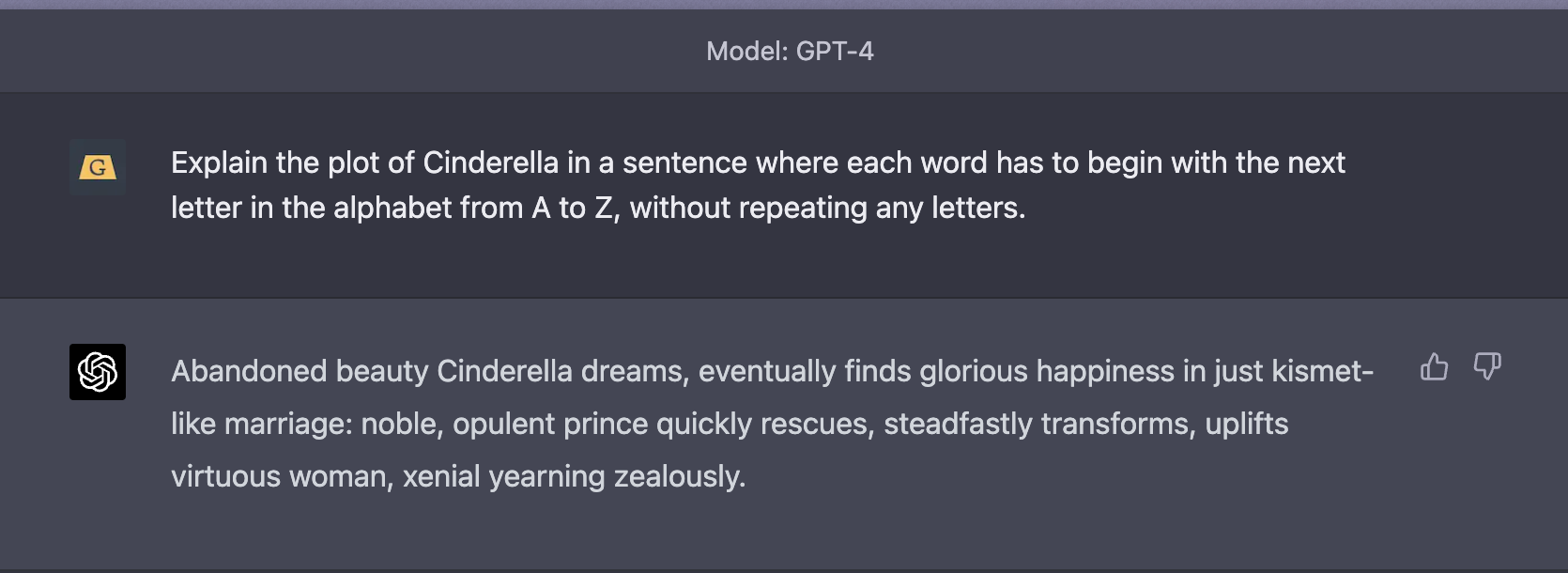
Where GPT-3.5 missed a bunch of letters between G and P, the new and improved GPT-4 had no problems with the same prompt.
GPT-4 has made vast improvements at taking tests used to measure human competency — it now measures in the 90th percentile of humans who took the Uniform Bar Exam (the test required to become a lawyer).
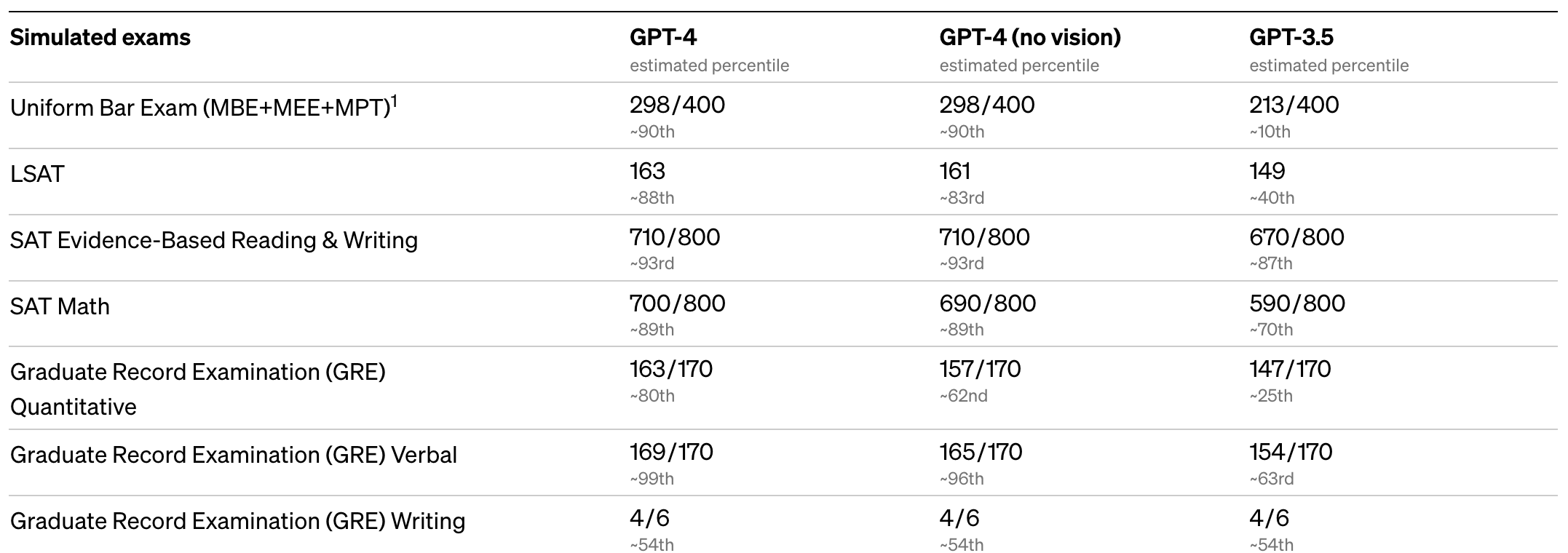
Note the GRE writing section results are the lowest out of all of these tests. This is a trend that extends to the results on high school AP exams, too.
GPT-4 crushes nearly ever AP test with 4's or 5's (usually enough to get college credit). But it still struggles with AP English Literature and Composition.
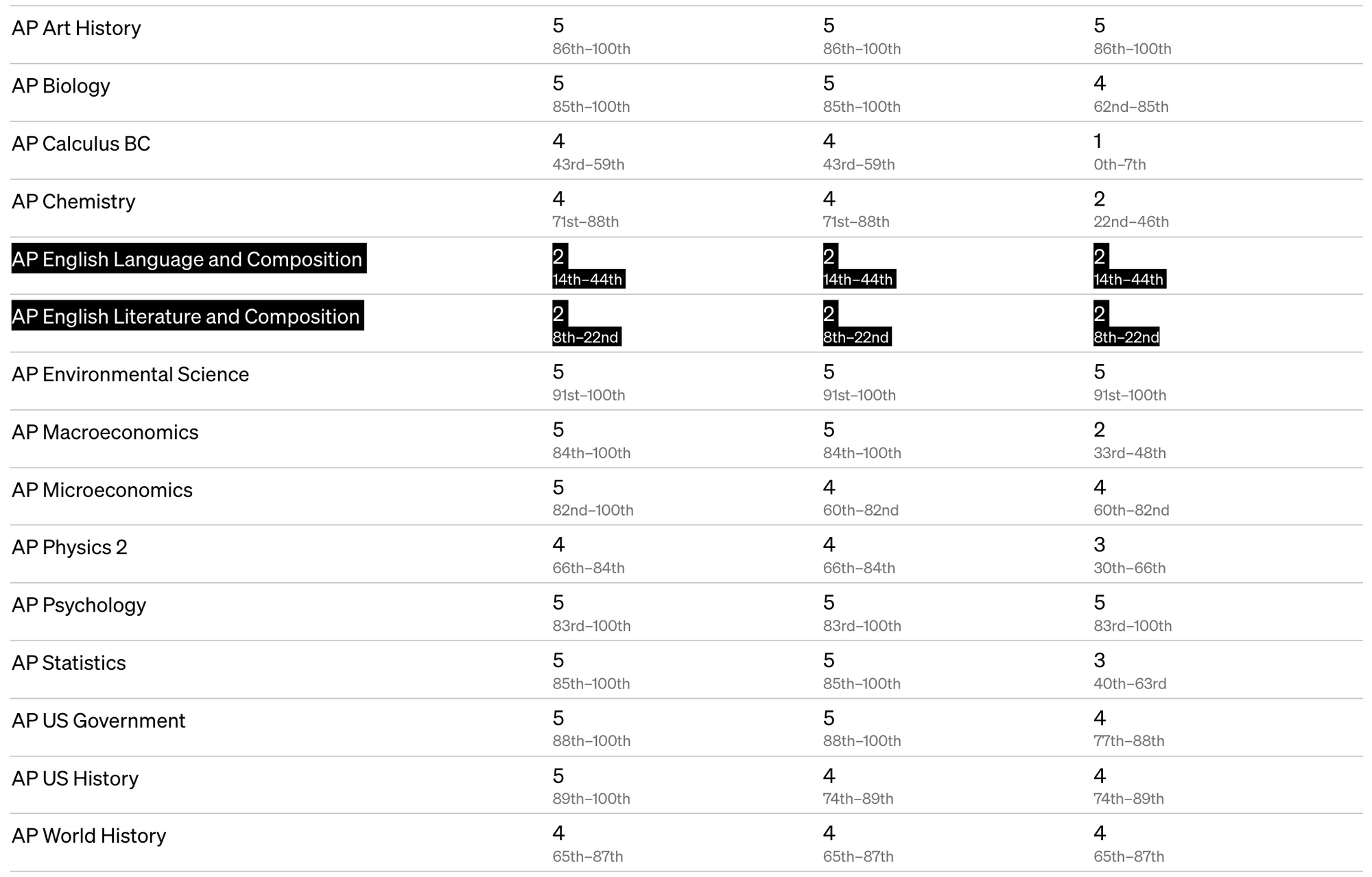
I find this oddly reassuring, even though in my heart I believe that this is going to change with future models. GPT-3 scored a 1 on AP Calculus but GPT-4 scored a 4. I remember getting a 3 when I took AP Calc.
The model really shines in its multimodal inputs — GPT-4 can understand why images are funny, or anticipate what might happen if something was changed in the image. This is the most impressive part of the new model’s capabilities, and it isn’t available to the public for testing (yet).
OpenAI is quick to point out that GPT-4 is prone to many of the same challenges as the previous models.
here is GPT-4, our most capable and aligned model yet. it is available today in our API (with a waitlist) and in ChatGPT+.https://t.co/2ZFC36xqAJ
— Sam Altman (@sama) March 14, 2023
it is still flawed, still limited, and it still seems more impressive on first use than it does after you spend more time with it.
Even if GPT-4 was ready months ago, it’s nice to know that OpenAI spent a lot of time fine-tuning this model. Sam also tweeted that they will be open sourcing the OpenAI Evals (their “framework for automated evaluation of AI model performance”).